- University of Illinois at Urbana-Champaign
Abstract
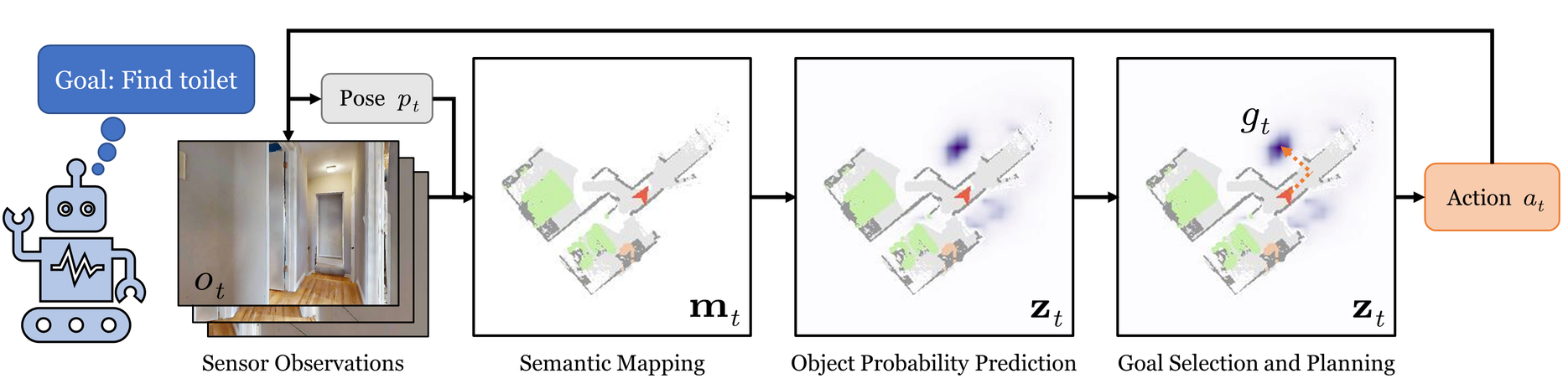
Efficient ObjectGoal navigation (ObjectNav) in novel environments requires an understanding of the spatial and semantic regularities in environment layouts.
In this work, we present a straightforward method for learning these regularities by predicting the locations of unobserved objects from incomplete semantic maps.
Our method differs from previous prediction-based navigation methods, such as frontier potential prediction or egocentric map completion,
by directly predicting unseen targets while leveraging the global context from all previously explored areas.
Our prediction model is lightweight and can be trained in a supervised manner using a relatively small amount of passively collected data.
Once trained, the model can be incorporated into a modular pipeline for ObjectNav without the need for any reinforcement learning.
We validate the effectiveness of our method on the HM3D and MP3D ObjectNav datasets. We find that it achieves the state-of-the-art on both datasets,
despite not using any additional data for training.
Predicting Unseen Objects
We visualize predictions made by our model in scenes from the val split of the Habitat-Matterport3D (HM3D) dataset.
The top row shows the agent's RGB observation, and the bottom row shows the incomplete semantic map overlaid with the target probability prediction.
Note that the prediction network only has access to the semantic map, not the RGB images.

Example ObjectNav Episodes
We visualize example episodes of ObjectNav using PEANUT on the HM3D (val). The left panel shows the agent's RGB observation.
The center panel shows the agent's semantic map overlaid with its target predictions heatmap, which is updated every ten steps.
The top right panel visualizes the distance-based weighting factor,
which is used to encourage the agent to search in closer areas before moving on to farther areas.
The bottom right panel shows the final value map, from which we take the argmax for goal selection.